の作業記録
準備を進める月曜日
- 作業記録の共有
- Textbox+朝の処理を変更しておく
8:00
おはようございます。本日はメルマガなどの準備を進めましょう。
Textbox:
全体で何をしようとしているのかを再検討します。
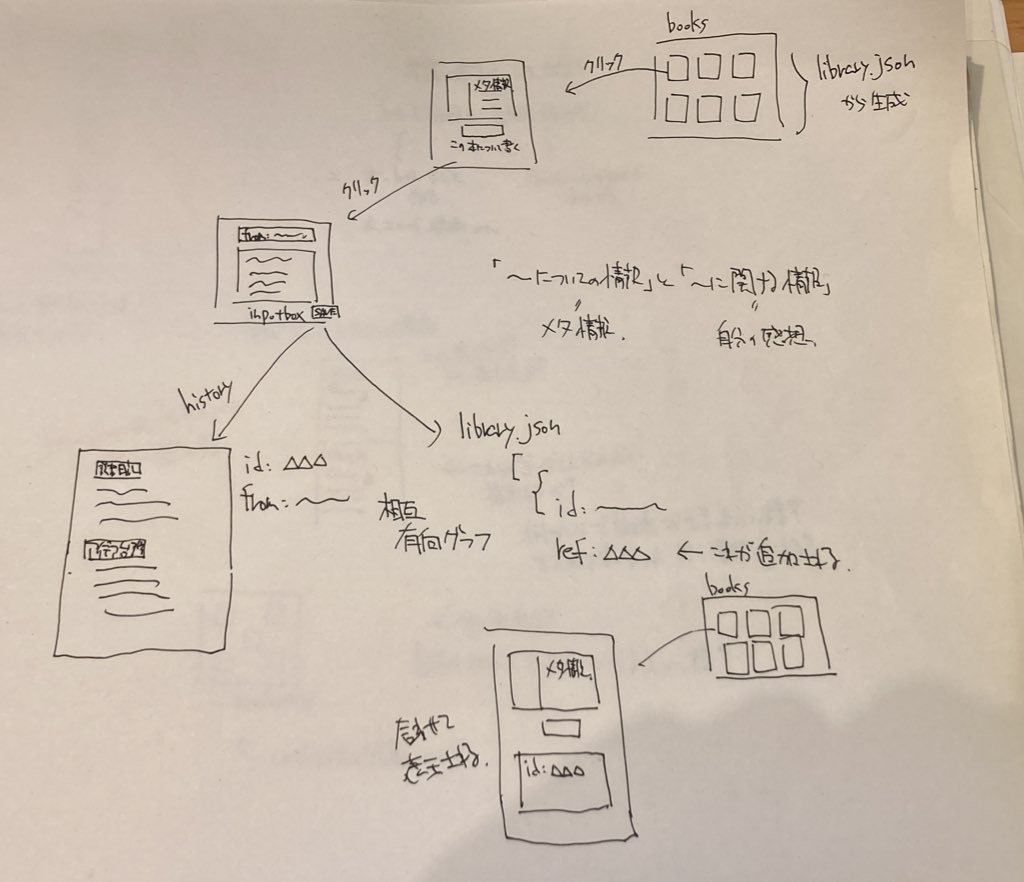
たとえば、以下はBooklogからのフィードを解析して作成されたjsonをもとに生成されているページです。

で、これが以前までの買った本の情報を取り扱うページ。

こちらはテキストベース。でもって、本の名前をクリックしたら赤字と黒字がトルグします。読了のチェック代わりです。
後者の以前スタイルはテキストしかもっていないのに対して、前者のjsonはテキスト+画像の形でもっているので、ボタンを押せばテキストだけの形にするといったことも可能です。で、読了のパラメータを持っておくなら、読了した本の書名を赤字にすることも不可能ではありません。
つまり、jsonベースにすれば以前のスタイルはほぼ不要ということです。ただし、テキストを編集するのとjsonを編集するのとではちょっと違いがあるので、そこを介入する必要はあるでしょう。
あとは、「2022年12月」のような仕切り(見出し)の存在です。そうしたものは、書影が並んでいる状態だと不要ですが、テキスト形式で並べる場合は必要でしょう(あるいはそうではないのかもしれませんが)。
表示を切り替えるときは、display:flexを解除するか、directionの方向を横ではなく立てにすればOK。buyのデータ(日付)も持っているので、それを表示すれば日付の仕切りも不要かもしれません。
ということは、必要なのは、Textboxから操作して対象のjsonファイルの既存の項目を操作する機能でしょう。
ダブルクリック→読了、というのは簡潔ですが、本にタグ付けしたりすることを考えるなら、それだけでは足りません。たとえば、クリックしたら詳細が表示され、そこからメタ情報が編集できる、という形の方がよいでしょう。
そうしたUIの実装と、編集後の内容をjsonに反映させる操作が必要です。
やりたいのは、その本を削除する、あるいはメタ情報を修正すること。書名かID名でjsonデータから対象の項目を見つけ出し、必要な処理を行う、という感じでしょうか。
問題は、それらの処理をクライアントサイド(JavaScript)でやるのか、サーバーサイド(Python)でやるのか、という点。
クライアントならば、jsonをfetchし、そのjsonに項目の修正などを行って、修正後の内容をサーバーに送り、サーバーはその内容をjsonファイル全体を上書きする、というやり方になるでしょう。非常に大雑把な感じがします。
サーバーサイドであれば、「編集したいJSONファイル名、編集後の項目」を送信し、Pythonはその項目からIDを見つけて、対象の項目を探して差し替え、という感じになるでしょうか。このとき、差し替える前のjsonを保存しておけばバックアップがききますね。
ある本を読了にするだけであれば、ID名だけ与えて、その項目のstateをdoneにして日付を与えればOKですが、しかしそれは「読了した日にダブルクリックする」という前提がつくのでやはりこれでは駄目ですね。詳細から読了日のパラメータを与えられる必要があります。
* * *
で、たとえば読書日記を書くときには、ここで本を探して、その詳細に書く、というのが一番自然なのかもしれません。
ただしその場合、「読書日記」だけを串座して並べることができません。やはりそれはちょっと違うような気もします。本ごとにこうして並んでいるのもいいですが、たとえば時系列で「読書日記」だけを並べてみたい気もします。どうするか。
* * *
「これについてのノートを書く」というアクションを作る?
9:00
メルマガ:
ファイルの準備だけしておきましょう。
* * *
ファイル設定だけはできました。
Textbox:
本の情報が入ったlibrary.jsonがあり、それを編集できるようにしたら便利では、という点は確認できた。
で、たとえば読書日記もその動作の延長線上に置くことができる。たとえば、books.mdで『惑う星』を探し、その詳細を開いたらメモ欄が出てくるので、そこに感想を書く、というスタイル。
こうすれば本を検索したりするのと同じように、自分の感想が検索できる。あるいは、自分の感想をキーにして本の情報を探すことができる(「あの登場人物が格好良かった本ってなんだっけ?」)。
一方で、library.jsonに入れ込んでしまうと、読書日記だけを取り出して並べることが難しい。不可能ではないが、「読書日記を書いた時系列」では並ばない。本が持つメタデータ順になってしまう。
読了日順にソートすればいい?
読書メモそれ自体にもメタ情報を持たせる?
読書メモを別途項目で作り、そのリンクを本の情報に入れ込む形にする?
いろいろ解決策がありそうだ。
library.jsonに保存しても、それだけを抽出すれば、串座しての閲覧は可能だが、たとえば別のページで、他のメモと読書メモを並べることはできるだろうか。一応可能ではあるか。本のメタ情報の一つに「メモ」を作ればいい。あるいは本のメタ情報のlineは、「メモ」として扱うようにすればいい。内容紹介はdescriptionsがあるので、そちらにいれたらOK。
一応、この形式でも他のページで情報を利用することはできそうだ。ただし、一冊の本のメモを数日書けて記録していくような場合は、読了日にすべてまとめられてしまう。その点をフレキシブルにするならば、メモそれ自体にメタ情報を持たせるしかない(入れ子構造にしてしまう)。
以上検討してみたが、「できなくはない」という感じだ。データを処理する方で頑張れば、先ほど検討した機能の実装だけで運用できる。
で、別のパターン。
* * *
「読書メモ」は読書メモとして別に項目を作り、その項目へのリンクを本のメタ情報として添えるやり方。
イメージしてるUIとしては、books.mdで本をクリックすると詳細(メタ情報)が表示される。で、下に「この本についてのノートを書く」というボタンが表示される。それを押すと、inputboxが表示され、そこにfromが設定されている。あとは読書日記タグをつけて、保存する。
すると、読書メモ項目がhistoryに追加されて、そこにはIDが設定されている。それと共に、library.jsonのその本の項目にも、「link」のような形でそのIDが追加される。
で、もう一度books.mdでその本の詳細をクリックすると、先ほど書いた読書メモも一緒に表示される。さらに新しくメモを追加することもできる。
という感じ。
全体的に悪くない。ただ、すごく面倒そうだが。特に、生成されたIDを、library.jsonにも渡すときがかなり面倒。jsonファイルを分けないで単一でやってもいいのかもしれない。ただ項目数が多くなると処理速度などが気になる。
ちょっと処理の流れを図にしてみよう。
ようは少し前まで考えていた「from」の機能を作り、さらにその結果をfrom元のjsonに反映させれば基本的にはOKだと言えそう。でもってやはり問題はファイル名。ファイルが分かれてしまっているので、「どのjsonのIDか」という指定が必要(あるいは、すべてのjsonファイルを走査するか(重複はないはず))。
あと、読書日記としての項目のIDは、それを生成するまで決定されないので、「同時」に両ファイルに追記はできない。まず、読書日記の項目を作り、その処理が終わったらIDをリターンして、そこからcallbackでrefを追記しないといけない。この処理がたぶん面倒。
* * *
jsonの属性としては「Referrer」がいいだろうか。「mention」という手もある。フラットにlinkにしてもいいし、Scrapboxのように「related」という言い方もある。
が、ここで意識されているのは「〜〜について言及している」という有向のグラフなので、linkだとその感じが薄れてしまう。Referrerでとりあえずはよいだろう。
ReferrerはIDを保存する? IDとタイトルを保存しておけば処理には困らない。タイトルが変更されたら?まあ面倒にはなりそうだが、全体の置換をすれば一応はいける。
12:00
Textbox:
情報を整理しながら実装を進めていきましょう。
まず、現状のinputboxで「作成」を行うとどんな処理が走るのか。
sendToHistory(arr,types)
という関数が起動する。arrには、保存する内容が配列で入っている。typeはlineなどの指定。
この関数は、内部で
appendtext(“history.json”,arr,types)
を実行する。上記はhistory.jsに含まれているが、appendtextはindex.html(のjs)に含まれている。つまり本体機能。
appendtextの実装は以下。
appendtext(filename,arr,flag)
その中で、以下をセットし、fetchでcgi-appendtext.cgiにpostしている。
| |
で、まずarrがどう作られているか。
| |
arrは配列だと思っていたが、jsonにパースされていたものだった(機能を書き換えたのに、名前を変えなかった弊害)。
渡しているデータは「{“body”:e.target.parentElement.parentElement.querySelector(".modal-body textarea”).value,“address”:getTagContents(),“image”:topimage}」で生成されている。ここにidを増やせばpyhonにidを渡すことができる。
次に、渡されるpythonファイル。cgi-appendtext.cgi
ここでは受け取ったjsonをbodyとして保存し、typeによって処理を分けている。で、基本的にはlineだからtypeがlineだったら、受け取ったファイル名のjsonを開き、次にjsonの新規項目作成し、開いたjsonに作成した項目を追加したものをファイルに上書きしている。
新しい項目のIDが発生するのはここ。もし、from欄に何かしらのIDが入力されていたら、どうしたらいいか。
新しい項目のIDが返ってきたら、記載されていたIDで既存項目を探し、そこにReferrerとして新しく生成されたIDを追記する、ということになるだろう。
新しい項目の作成 makeJsonDate.makeLinelist(contents[“body”],contents[“address”],contents[“image”]) で行っている。これは項目を作成した上で、それを返す処理だ。その返ってくる項目の中にIDが含まれている。
もし、from欄に値が入っているならば、そのIDを使って処理する、という関数を書けばいい。よってまず、新規項目を直接jsonに追加にいれるのではなく、変数に放り込むことにしよう。
現状。
| |
変更後。
| |
Referrer処理の関数に渡すものはなんだろうか。対象となる項目のID名、Referrer付与するID名(とタイトル?)、対象となる項目が存在する(はずの)jsonファイル名、あたりか。
ID名からその項目が存在するjsonファイルを探す、ということもできる。ID名に重複がなければ基本的に力技で済むだろう。特定のフォルダ内に存在するjsonファイルを走査すればいいだけだから。当然、ファイルと項目が増えれば結果が返ってくるまでの時間はかかる。
inputboxのID欄にIdを入力するときに隠し要素としてファイル名を添付する作戦もある。あるいはdo/id名のような表記をして後で分離してもいい。あるいは、id名そのものにファイル名を添付しておく?いや、さすがにそれはばからしいか。
できるだけ柔軟性の高い(そしてメンテナンスがしやすい)方法にしたい。historyと他のjsonでIDの重複がないなら全走査も手だし、重なるのがその二系列だけなら、historyは除外して(あるいはhistoryだけ)を走査する、という手もある。
ふむ。
一応、今考えているのはbooks.mdから生成する場合で、その項目が含まれているのはlibrary.jsと決まっている。よって本の詳細をクリックしたときに設定されるIDに、「library.js」を添えること自体は難しくない。逆に、ごく普通にinputboxを開いてIDを指定するときはどうなるか。その場合は、何かしらで絞り込みが必要で、以前はそれをaddressで間接的に限定しようとしていたが、それでいいのか。
ここで本についての言及は、books.mdからしかできないようにする、としておけば実装は薔薇のように綺麗に整う。そして、ユーザーの利便性が落ちる。
idを入力するときに、ファイルをセレクターから選べるようにしておく? これはそこまで無理な話しではないだろう。選択肢はあるフォルダに含まれるすべてのjsonファイルとしていい。絞り込みはそこから行われる。
こうすればファイル名を添えるのは難しくない。少しだけ野暮ったいが、「ファイル」という確固たるものを扱うにはこれが一番てっとり早いかもしれない。
15:00
Textbox:
まずは入力欄から作りましょう。
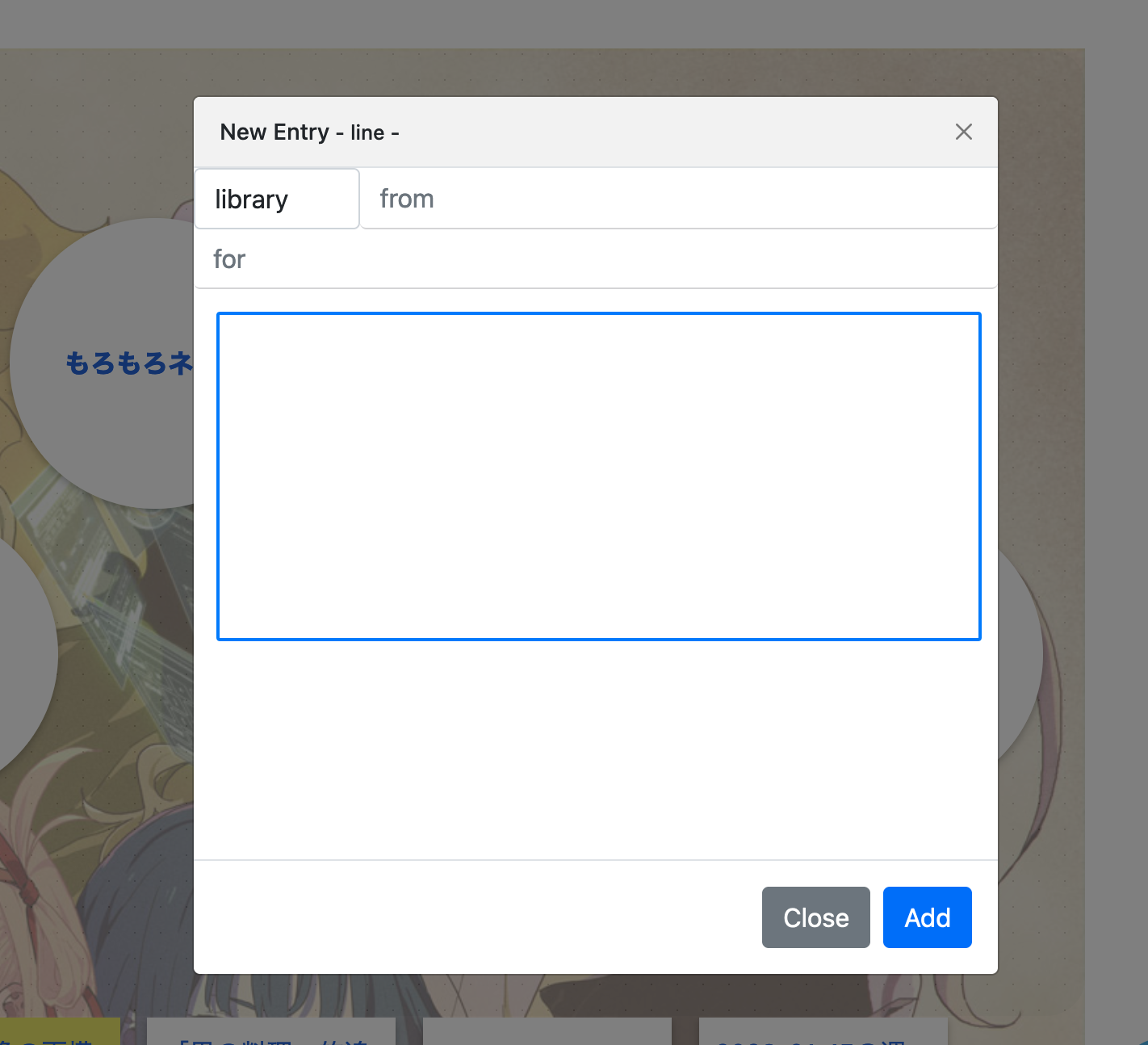
selectboxの中身は手入力です。これはまあ、これでもいいでしょう。Textboxに最初にアクセスしたときに、jsonフォルダの中身を取得し、その結果からoption(選択肢)を作れるようにしておくのが一番ですが。
いちおうapiを作りましょうか。Pythonで指定されたフォルダの中身をリストで返す、的なものにしましょうか。あるいはこれもjsonを作るか。
* * *
jsonを作りました。jsonフォルダの中にあるjsonファイルの一覧を保存するjson.jsonファイルを自動的に作るようにしました。もちろんそのファイルもjsonフォルダにあります(ややこしい)。
16:00
Textbox:
次に、fromの中身を保存する処理です。先ほど確認した関数に変更を加えればOKですね。
* * *
from欄を保存する機能ができました。from欄にテキストが入っていたら、selectboxの中身と共に保存し、そうでなければ空欄で保存します。
17:00
Textbox:
続きの処理を書きます。
* * *
かなり大詰めですが、気がつきました。fromでファイル名を指定するとして、新しく作成された項目のIDもまた「どのファイル問題」を持っています。adrress欄に入っているものを添付する? address欄は複数設定できるが、そのときはどうする? 空白ならhistoryで良いか? それともhistoryに統一するか?
いや、さすがにそれは変だろう。何もなければhistroyでいいが、そうでない場合は住所を指定するのが自然。
やはり、IDだけにして、全部から探すことにしようか。
ただinputboxで「from」を入力するときは「書名から探す」ということをしたいので、そこでの絞り込みはあってもいい。で、そこで絞り込まれているのだったら一応データとして保存しておくのはよいとも思う。別段それを必ず使わなければならない、というわけでもないだろう。
* * *
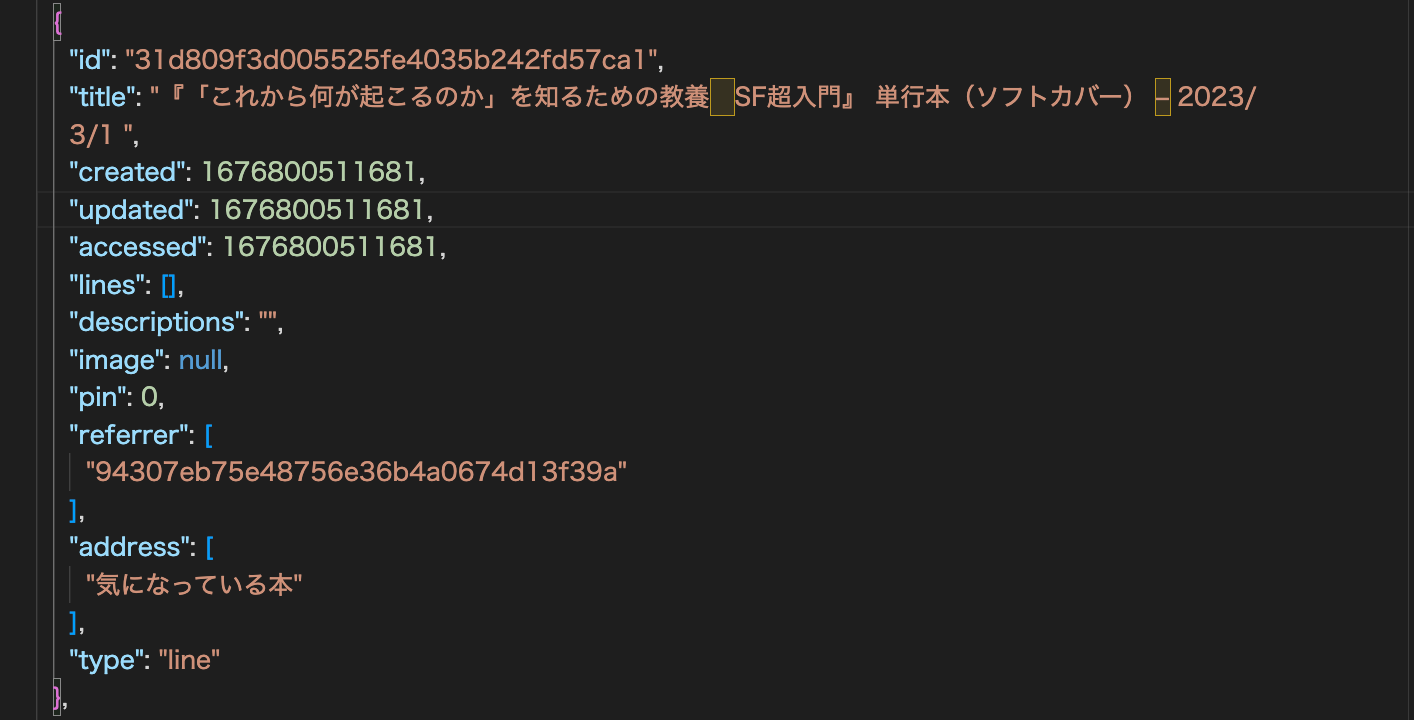
とりあえず、idがあったら、そこにバックリンク(referrer)を追加することができるようになりました。問題はここからです。
* * *
もう一度、初期値で考えてみましょう。booksで本の一覧が表示されて、どれかの本をクリックしたら詳細が表示される。で、「この本についてノートを取る」というボタンを押せば、その本のIDがfrom欄に入ったinputboxが開く。で、メモを取って保存を押す。すると、項目が生成されるわけですが、当然送り先があるでしょう。「読書日記」です。現状読書日記はhistoryだけに存在しています。読書日記.jsonはありません。作るにしても「日記」.jsonになるでしょうか。
ここが分水嶺ですね。読書日記をhistoryに留めるなら、idの指定はなくても大丈夫です。しかし、別のjsonに、あるいはにも保存するならばちょっと思案が必要です。
histroyにおけるaddressは現状「タグ」の役割です。しかしここでは本当にどこかのjsonに送るかどうかを決めなければなりません。これは簡単なことではないので、ちょっと考えてみましょう。