の作業記録
ややゆっくりする火曜日
- 作業記録の共有
- 結城メルマガ読む
- Textbox+タスクの一覧
- LB+作業の整理
- LB+こなゆきさんの原稿を配置する
- LB+こなゆきさんの原稿の記法を揃える
- 『Re:vision』+epubの読み返し+の準備
- TH+002
- Twitter的日記について
10:00
おはようございます。今日は疲れの足跡を感じるので、全体的にゆっくりめに過ごします。
fragment:Twitter的日記について:
アイデアノートの「使い方」の例からいって、箇条書きで情報を書きつけておけば、後から処理しやすい、ということは言えるように思う。これと「日記的なもの」をどう組み合わせるか。
11:00
妻の就職準備など:
12:00
結城メルマガ:
読みます。
* * *
読みました。
たとえば、上のような記事(ないしはそのリンク)を「日記」として扱えないだろうか。
つまり、Scrapbox+自作のシステム?
リンクを使うなら、Scrapboxに限定はされないか。
Twitterのbotにする?→著作権周りが怪しいか。
Textbox:
すべてのtodoファイルを扱えないか。
Dropbox直下にたくさんのフォルダがある。それぞれが(おおむね)一つのプロジェクトに対応している。で、それらのフォルダの中に、たまにtodoという名前のファイルがある。そのプロジェクトのやることを記載したファイル。
基本的に、そのプロジェクトを作業するときに、そのファイルを参照するから別にそれで構わないのだが、一覧できたら嬉しいだろうか。
ターミナルで出力するか、mdファイルに書き出してtextboxで閲覧するか。
* * *
すべてのフォルダをwalkするので結構時間がかかるかもしれないが、やってみないと分からない。
todo.txt,todo.mdというファイルを探し回り、見つけたらそのファイルからtodo項目だけを抜き出す?
ファイルの中身全てを抜き出してもいいが、さすがに情報量が多すぎるだろう。むしろ、todoだけだからこそ一覧する意味がある。
文芸的タスク管理。つまり、おおもとのファイルは文脈+タスクが記載されていて、一覧では、タスクだけを抜粋して表示させられる、というような。
うん、面白そう。ちょっと考えてみよう。
* * *
シェルスクリプトでも書けそうだが、Pythonを使う。
まずosをimportするところからのスタート。
* * *
まず骨子。
| |
実行したら、ちょっとだけ待たされた。まあ、そりゃそうだが、ちょっとだけで済んだのは驚きでもある。Dropbox直下にプロジェクトだけを入れておくフォルダを作れば、検索範囲は限定できるが、そうなるとムダな階層構造が生まれるのでここではこのままの状態にする。
あとは、見つけたファイルを開いて、何かしらの処理を行う。
* * *
ファイルを開こうとしたけども、ファイル名だけでフルパスではないので失敗した。curDir, dirs,の両方が必要で、しかもそれぞれがリストになっているので、だいぶややこしい。
路線変更。
| |
これでフルパスで名前が取得できる。
* * *
OKです。無事ファイルを開くことができました。
あとは、todo行のpickup。マークダウン記法が基本ですが、行頭に制限するかどうか。インデントされているものもあるだろうから、記法があればそれでよしとしましょう。
* * *
| |
できました。これで抜き出しは可能。あとは、それをどう処理するか。
あと、プロジェクトの名前が必要ですね。
* * *
こんな感じになった。
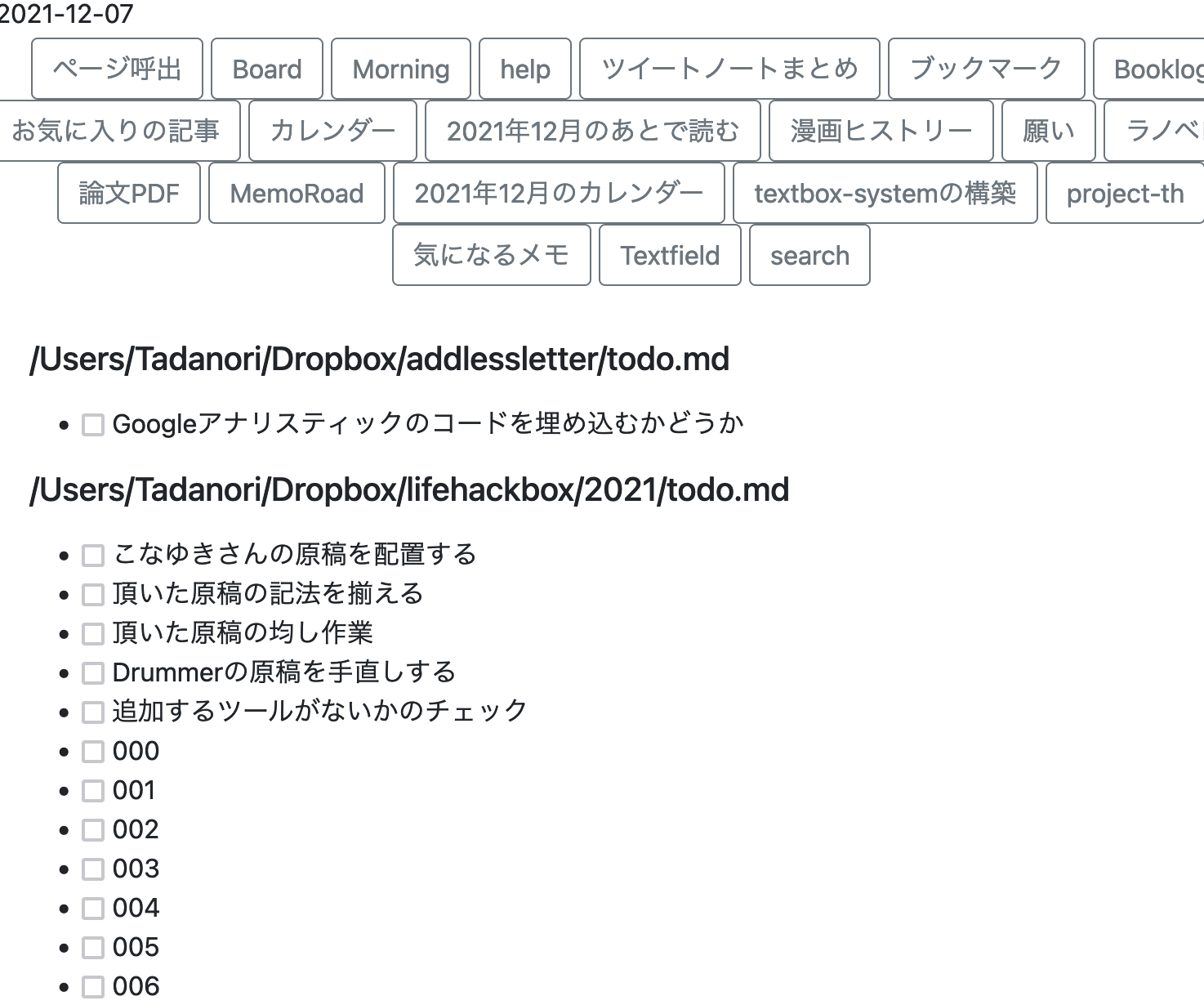
悪くはない。ちょっと思ったのだが、フォルダ名などが邪魔なのでそれを取り除こうと思ったが、むしろこのファイル名をクリックしたら、vs codeでそのファイルが開くようにすればいいのではないか。
だとしたら、どうしたらいい?
Textboxの機能になる。
まず、整形しよう。改行を整える。
* * *
できました。もともとVS Codeで開く、という機能があったので、それを流用することできました。
当初考えていなかった機能ですが、めちゃ便利になりましたね。
完全に完了したプロジェクトは、todoをdoneに変更して、拾われないようにし、継続中だけとも喫緊のタスクがないものはファイル名だけ表示される、という按配は良さそうです。
14:00
LB:
頂いた原稿を配置します。一応これですべてなはずです。
* * *
配置して、URLの記法をre:viewsの記法に揃えました。
『Re:vision』:
ゲラ的なepubファイルをiPhoneで読めるようにしておきましょう。といってもDropboxからbookアプリに読み込むだけですが。
* * *
OKです。時間を見て、また読みながら確認を進めていきましょう。
17:00
Twitter的日記:
なんとなく、イメージはあるのだけども、具体的に自分が何をしたいのかがはっきりしていない。
「日記」に関する課題をデジタル的に解決しようという雰囲気はわかるが、それだけだ。
そもそも、現状は、日記的なものはぜんぜん書いていない。その上で、自分は何をしようとしているのか。
publish:ブックカタリスト:BC026『Humankind 希望の歴史』 - by 倉下忠憲@rashita2 - ブックカタリスト
一つには、この作業記録内に記述したことと「再会」したいような気持ちがある。たぶん、それがこの一連の思考のきっかけだったように思う。そこから、何か読んだ本や印象的な言葉と再会して、愉しむ、みたいな方向に広がってきた。
で、それらのデータのうちのいくつかは、Textboxに保存されている。あとで読むとかお気に入り記事とか名言集とか、自分のアウトプット履歴とか、そうしたもの。
「気になる本」に入れたものを取り出す。あるいは、「買ってまだ読み終えていない本」など。そうしたものの存在を私自身にコールバックする。そういう仕組み。そうしたものを求めているのだろうか。
いつ、自分はそうしたコールバックを受け取り、そして処理を実行するだろうか。アイデアノートのように、毎朝一回だろうか。あるいは、Twitterのようなタイムラインを作って、そこに1分ごとに新しいリマインドが追加される形だろうか。
* * *
まだ、やろうとしていることの象が結び難い。
* * *
日記を情報カードに書く、という所作。そこから学べることは何かあるだろうか。
一イベント一ファイルで作成すれば、データは扱いやすくなる。しかし、それを作成する手間が少しある。どこにどのように保存するのかも厄介な問題が多そうだ。
その点Twitterはすごく楽だ。開いて書き込んでTweetのボタンを押すだけで、その情報が書き込まれる。クラウドに。
その感覚と、先ほどのいろいろな情報を「再利用」したい気持ちが混じり合っている。
* * *
箇条書きというか、一行一データの形で書いておけば、自分のコード資産でそれを処理できる。まずそれをベースで考えるべきだろうか。
* * *
たとえば、この作業記録は、おおもとになるmdファイルがあって、そのデータをベースにhugo用のデータを生成している。おかげで、公開する情報とそうしない情報を一ファイルで切り分けることができている。
で、これまで作業記録の「ブロック処理」について考えていたわけだが、たとえばもとのファイルでは一行で書いておいて、hugo用のファイルにはそれをブロック形式に変換することで、データ利用と見た目の良さの二つが使えるのではないか。
一応、理屈は通る。
このファイルでは、
block:タイトル:内容
のように書いておくと、hugo用には見出しと本文に変換されて記述される、で、自分用のファイルには行単位で保存されていく、という格好。
ふむ。
* * *
仮にそういうやり方をするとして、では、そこに何を書くだろうか。
自分が書いた記事(publish)なんかも、ランダムに表示されると面白いような気がするし、あるいは去年の同じ日付に書いた記事が表示されても面白い。この場合、アプローチはだいぶ違ってくる。
後者は、日付のデータ+内容データという情報を残しておき、その日の日付から、そうした過去データをピックアップすることになるだろう。作業記録のサマリーを準備するならば、それも表示させられる。
作業記録にサマリー欄を設ける?→あるいは、一日の振り返りをサマリーとするか。それはありえそう。
push :貧乏な人ほど投票できる票数が多いとしたらどんな政治になるだろうか。
* * *
たとえば、引用集.mdというページは以下のような感じになっている。

ブロックだ。しかし、よくよく考えれば、以下のように書き換えてもHTMLでの表示は変わらない。

これだと、行で操作ができる。
ふむ。
ということは、この引用集のページからランダムに抜き出すことは、これまでのコード資産で可能である、ということになる。
では、抜き出したものを、どう表示させるか。